异常检测综述
定义
时序异常检测通常形式化为根据某种标准或正常信号寻找离群数据点。有很多异常类型,从商业角度来说最重要的类型,包括意料之外的峰谷、趋势变动、水平变化。
基本上,异常检测算法要么将每个时间点标记为异常/非异常,要么预测某一点的信号,并测试这一点的值和预测值的偏离程度,以认定异常。
异常分类
-
innovational outlier (IO):造成离群点干扰不仅作用于X(T),而且影响T时刻以后序列的所有观察值。
-
additive outlier (AO):造成这种离群点的干扰,只影响该干扰发生的那一个时刻T上的序列值,而不影响该时刻以后的序列值。
-
level shift (LS):造成这种离群点的干扰是在某一时刻T,系统的结构发生了变化,并持续影响T时刻以后的所有行为,在数列上往往表现出T时刻前后的序列均值发生水平位移。
-
temporary change (TC):造成这种离群点的干扰是在T时刻干扰发生时具有一定初始效应,以后随时间根据衰减因子的大小呈指数衰减。

常见方法

STL分解(统计方法)
STL(Seasonal and Trend decomposition using Loess )是以鲁棒局部加权回归作为平滑方法的时间序列分解方法。
存在季节性因素的时间序列数据可以被分解为趋势因子(Trend)、季节性因子(Seasonal)、和随机因子/残差(Irregular)。此时可以通过相加模型或者相乘模型来分解数据。
- 相加模型:Yt = Trendt + Seasonalt + Irregulart
- 相乘模型:Yt = Trendt x Seasonalt x Irregulart
在R中,stl()可以很好的处理相加模型,至于相乘模型,仅需要进行一下对数变换就可以转化为相加模型了。

数据如果有异常,都会体现在残差数据集中。我们怎么从残差数据中早出有问题的数据时间点呢?
我们可以利用3-sigma原则:当残差数据近似正态分布时,我们计算出残差数据集的标准差,如果数据点与均值的差值在3倍标准差以外,则认为是异常点。
ARIMA(统计方法)
自回归移动平均模型(ARIMA)是一种非常强大的时间序列拟合模型,它可以对非平稳的无季节效应的时间序列进行拟合和预测。
AR模型
AR模型(Autoregressive model)即自回归模型,用同一变数x之前各期,即xt-p至xt-1来预测本期xt的表现,并假设它们为一线性关系.
- 描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测
- AR§模型结构:
- PACF,偏自相关函数(决定p值)
MA模型
MA模型(moving average model),即移动平均模型,序列当前时刻的时序值是过去q阶白噪声的线性组合
- 移动平均模型关注的是自回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动
- MA(q)模型结构:
- ACF,自相关函数(决定q值)
ARMA模型
ARMA模型就是二者的结合,是目前最常用的平稳序列拟合和预测模型。
- ARMA(p,q)模型结构:
ARIMA模型
ARMA模型只适用于平稳性序列,那么如何拟合非平稳序列呢?
差分运算具有强大的确定性信息提取能力,许多非平稳序列差分后会显示出平稳序列的性质。
根据这个特点,我们就可以将非平稳序列进行差分运算后变为平稳序列,在用ARMA模型拟合。这就是ARIMA模型(Autoregressive Integrated Moving Average model),即自回归差分移动平均模型。
ARIMA共有三个参数,p,d,q。可分别根据PACF、差分运算、ACF得到。
建模步骤:

在R中,arima(ts,order=c(p,d,q)),forecast包中有一个函数auto.arima(ts)可以实现最优ARIMA模型的自动选取


预测:forecast(fit,n),fit为拟合模型,n为向后预测的时间点个数。一般向后预测越多,结果越不准确。
1 | >forecast(fit,3) |

深灰色表示80%的置信区间,浅灰色表示90%的置信区间。
异常检测就可以将预测结果和实际结果进行比较,如果实际值在置信区间外,可以认定为异常。
至于带季节性的非平稳序列,可以通过STL分解得到残差数据,再对其进行预测。
R中也有简单的实现,只需在arima()中增加一个参数seasonal就可以了。
使用R中的tsoutliers包可以方便地检测时间序列中的离群值
LOF(机器学习方法)
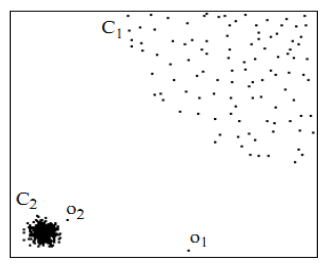
对于C1集合的点,整体间距,密度,分散情况较为均匀一致,可以认为是同一簇;对于C2集合的点,同样可认为是一簇。o1、o2点相对孤立,可以认为是异常点或离散点。现在的问题是,如何实现算法的通用性,可以满足C1和C2这种密度分散情况迥异的集合的异常点识别。
定义
-
d(p,o):两点p,o之间的距离
-
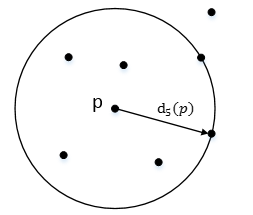
k-distance:第k距离
对于点p的第k距离dk§ = d(p,q),其中q是距离p第k远的点
-
第k距离邻域NK§,就是p的第k距离即以内的所有点,包括第k距离。
-
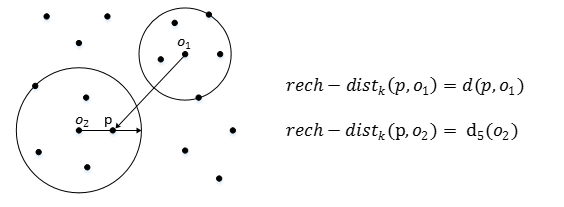
reach-distance:可达距离
点o到点p的第k可达距离:rech-distk(p,o) = max{d(p,o),dk(o)}
-
local reachability density:局部可达密度
点p的局部可达密度表示为:
\operatorname{lrd}_{k}(p)=1 /\left(\frac{\sum_{o \in N_{k}(p)} r e a c h-\operatorname{dist}_{k}(p, o)}{\left|N_{k}(p)\right|}\right) 表示点p的第k邻域内点到p的平均可达距离的倒数。
局部可达密度与总体密度类似,只不过是用k距离邻域计算的,所以称为“局部”。如果p是孤立点,那么点o到点p的可达距离会取到o,p的实际距离,这样计算出来结果就要小。
-
local outlier factor:局部离群因子
点p的局部离群因子表示为:
L O F_{k}(p)=\frac{\sum_{o \in N_{k}(p)} \frac{\operatorname{lrd}_{k}(o)}{l_{r d_{k}(p)}}}{\left|N_{k}(p)\right|} = \frac{\sum_{o \in N_{k}(p)} l r d_{k}(o)}{\left|N_{k}(p)\right|} / l r d_{k}(p) 表示点p的邻域点 Nk§Nk§的局部可达密度与点p的局部可达密度之比的平均数。
如果这个比值越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;如果这个比值越小于1,说明p的密度高于其邻域点密度,p为密集点;如果这个比值越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
在R中使用:
1 | library(DMwR) |
应用到时间序列即不考虑时间前后相关性,以孤立散点进行检测。
LSTM
LSTM( long short term memory)即长短记忆神经网络,是为了解决RNN网络只能保留近期信息而设计出来的网络结构,它可以选择性地记住或遗忘历史信息。

黄色的框代表神经网络层,是整个网络中非常关键的一部分
- Xt代表输入信息,是一个时间点的全部信息
- ht代表输出信息
- 一个绿色框代表一个细胞(cell),顶部贯穿细胞的横线表示细胞状态,它选择性地保留了历史的输入信息
遗忘门

遗忘门决定遗忘哪些信息,它的作用就是遗忘掉老的不用的旧的信息,遗忘门接收上一时刻输出信息ht−1
和当前时刻的输入xt,然后得到一个遗忘矩阵ft来决定遗忘过去信息Ct-1的哪些部分。
输入门

它决定了从新的信息中存储哪些信息到细胞状态中去。即产生要更新的信息。
sigmoid 层和tanh层分别接受两个输入,产生it(决定了要更新哪些信息)和(决定了信息内容),然后更新细胞状态:

输出门

首先利用输出门(sigmoid层)产生一个输出矩阵Ot,决定输出当前状态Ct 的哪些部分。接着状态Ct 通过tanh层之后与Ot 相乘,成为输出的内容ht
LSTM-AE

LSTM-AE就是将自编码器的编码和解码部分都用LSTM来代替,既可以实现降维,也可以缩短序列长度,提取信息。
Encoder:结合LSTM的性质, 在任意时刻的隐含状态,同时受到当前时刻的输入和过去时刻隐含状态的影响。注意,最终只有i时刻的隐含状态传递给了decoder部分。所以,满足:
Decoder: 与encoder的过程相反,decoder从i时刻逐一向i-4时刻遍历。所以当前时刻的隐含状态会受到当前时刻和下一个时刻隐含状态的影响